Building a Local LLM Playground with Ollama on Proxmox - Part 1

Are you working with LLMs and constantly keeping an eye on token usage and monthly subscriptions to keep costs down? Maybe you're a Mac coder with a Windows gaming rig, wishing you could tap into all that unused GPU power from the comfort of your laptop? If so, stick around. This post might be just for you.
In this post, the first of a series, I’ll share the solution I used to create a robust, reliable LLM playground that runs on a dedicated workstation on a local network, offering near-limitless possibilities for virtualizing machines and containers to serve up complete clusters of services for your development needs.
Three key components of this architecture are:

- Proxmox, an open-source virtualization platform that delivers rock-solid performance using Linux KVM/QEMU and features a highly capable UI & API
- Ollama, a cross-platform LLM server which lets you download and run models like Llama 3.3, DeepSeek-R1, Phi-4, Mistral, Gemma 3, and others
- Open WebUI, an extensible, self-hosted UI to interface with local models, offering teams a low/no-code method of experimenting with tools and prompts.
The Problem
In 2020, I was working increasingly with data science teams and projects, having come to it via data warehousing, web development, and distributed systems; because of my early experiences, infrastructure has always been important to me. So, when I started learning AI/ML, I insisted on doing so bottom-to-top, understanding every layer of the stack on the way to performing linear regression, starting with bare metal. This meant my first task was obtaining a GPU.
However, from 2020 to 2022, a perfect storm of supply chain disruptions from COVID-19, global semiconductor shortages, and skyrocketing demand from cryptocurrency mining made buying a GPU extremely difficult. NVIDIA and AMD GPUs were heavily scalped, and finding entry-level hardware for even basic AI/ML experimentation was a major challenge.
Given the scarcity at the time, I was determined to squeeze every last penny out of my purchase once I got a hold of suitable hardware for my learnings. So, I set out planning a dev environment that could satisfy the following:
- I could use the GPU for LLMs when coding
- I could use the GPU for games when not coding
- I could use whatever CPU was leftover for other uses
1 could already be solved by running Ollama directly on my MacBook or M1 Mini. But, since Macs aren't exactly made for gaming, their performance can't compete with a dedicated NVIDIA card (and, no, don't get me started on Metal).
2 could be solved with a Windows PC exposing Ollama on my network, but since I'm a Mac guy, all the rest of its hardware would be practically unusable to me (and, yes, I've thoroughly investigated Linux VMs using both Hyper-V and WSL).
Thus, 3 became an exercise in finding a virtualization platform to satisfy 1 and 2, to provide VMs when I wasn't using the LLM. Given my previous attempts with Windows hypervisors ended in frustration, I started to look again at Linux. Particularly, I needed an option that would easily and reliably provide one key component: PCI passthrough, allowing a single VM to access the GPU as if it were native.
A First Attempt
I had attempted something similar using an old Dell workstation with a GeForce GTX 960, which I had originally bought in part to attempt a Hackintosh (and later scrapped due to its complexity). Following Bryan Steiner's excellent gpu-passthrough-tutorial, I had successfully built an Ubuntu server with QEMU/KVM running Windows 10 and fully accelerated graphics.
This worked, but had its problems. It was CLI-only, configured and ran solely via scripts, and often crashed, locking up guest and host machine with it. Still, it proved the concept. I used it for about a year, occasionally running other VMs for small workloads, but not exercising it too rigorously. I eventually got annoyed by working without a UI (never having got virt-manager to work correctly with passthrough) and eventually reconfigured the machine for more generic uses.
I mostly forgot about this experiment, until I started building RAG pipelines for work, at which point I thought I'd get serious about building a better alternative. So, I decided to give a certain VM platform a spin that I had heard about...
Enter Proxmox
Proxmox is an open-source virtualization platform that offers a comprehensive suite of tools for building, managing, and maintaining virtualized environments. It’s built on KVM/QEMU for virtualization and LXC for containerization, allowing you to virtualize entire machines or run isolated application images – think Docker with benefits, such as an integrated UI.
Here is the complete setup:
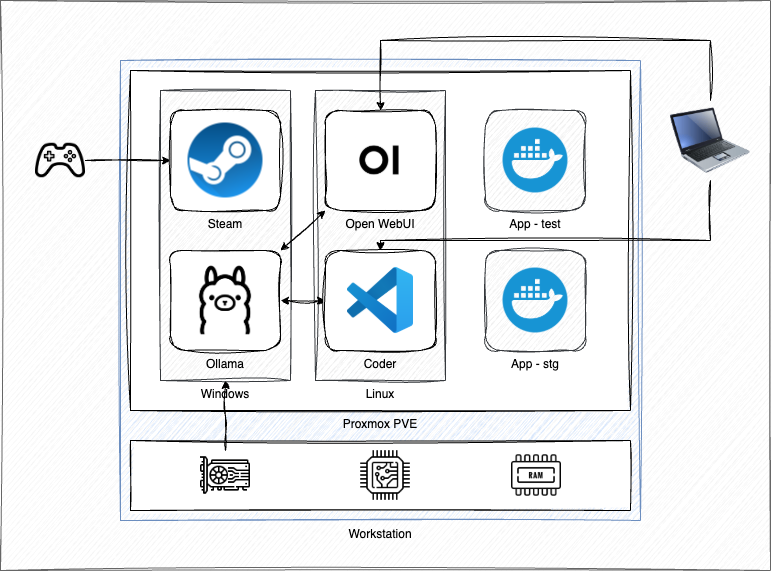
- Proxmox PVE running on a single workstation
- Windows 11 running in one Proxmox VM
- Hardware GPU passed through to the Windows VM
- Ollama serving LLMs using the host GPU via PCI passthrough
- Ubuntu 24.04 running in another Proxmox VM
- Coder providing remote VS Code dev environments
- Open WebUI serving a familiar web UI to Ollama
- Proxmox LXC containers running supporting services
I work primarily from a Mac, and occasionally game with an Xbox controller, which can be passed through to the Windows VM via USB dongle. A Logitech MX Keys and Mouse combo provide input switching, along with a single Dell monitor for video output (virtual displays are possible in Proxmox, but not needed when you can plug a video cable directly into the GPU.)
My development workflow looks something like this:
- Open MacBook and select a project via:
- Coder web UI running in the Linux VM as a service
- Remote-SSH from VS Code to Linux VM itself
- Commit code to Git, push to internal repo/service running on Proxmox
- Navigate to local Open WebUI for LLM use and evaluation
This skips a lot of steps, but we will get into those in later posts. I run Open WebUI, Caddy, and MLflow can all be run in the Linux VM, or, better yet, in dedicated LXC containers on the main Proxmox host.
Server Specs
This machine cost $1200 on sale from a fancy electronics store, but there's no reason it couldn't have come from Costco. With a little research into general requirements and a recent enough GPU, there's no reason this couldn't be duplicated with any commodity, off-the-shelf hardware.
- HP OMEN - 40L Gaming Desktop
- AMD Ryzen 7 7700
- 16GB DDR5 Memory
- NVIDIA GeForce RTX 4060 Ti
- 1TB SSD
Gussy It Up However You Want, Man...

After a year of using this platform for both development and gaming, I can say, without hesitation, it works extremely well. I rarely encounter problems, and, when I do, I simply reboot the problematic VM from the Proxmox UI, all remotely.
Regarding performance, I'd be hard pressed to find any indication I'm gaming in a VM (yes, even CoD Black Ops 6!) Even while co-hosting a few production services, I've yet to see them bog down the performance of the GPU.
Similarly, LLM performance is completely unhindered by the virtualization, again thanks to the passthrough. Plus, I have nearly unlimited options for application deployment:
- I can add more, or mightier resources to my Linux VM
- I can add multiple Docker containers within it (with no DinD worries!)
- Or, I could launch LXC containers with full Proxmox UI support
All in a single, multi-OS workstation.
Conclusion
While I hope I have made this introduction accessible to data scientists, ML engineers, and other software developers working with LLMs, please note this path is not for everyone! Virtualization does increase complexity, and it can break in novel ways that can feel overwhelming at times.
However, if you are concerned about privacy, or plan to expand your development footprint into managing clusters of microservices and associated tooling, Proxmox provides an excellent platform to start building on affordable commodity hardware in your own private cloud.
Next Steps
I've focused on Proxmox in this post, and barely scratched the surface of how it integrates with Ollama and Open WebUI. In future posts, I plan to address that, as we dive deeper into how to build a complete ecosystem around your LLM using:
- Compute clusters, adding nodes and managing VMs across them
- Distributed storage, providing replicated block and file-based stores with Ceph
- Data backup, with or without a dedicated Promox Backup Server
Until then!